根据您的反馈,既然 CPU 模式下 faster-whisper 依然大量漏听,这表明问题可能超出了参数调整的范围,可能与音频源本身或模型与音频的兼容性有关。
关于您询问的 SenseVoice 集成问题:
目前 pyVideoTrans 软件本身并未内置 SenseVoice 作为可选的语音识别渠道。 您提到的可能是通过其他方式或未来版本可能支持。
当前可行的解决方案是使用软件内已有的、效果更好的在线AI语音识别渠道:
强烈推荐:使用在线AI识别渠道
- 在“语音识别渠道”下拉菜单中,选择
OpenAI语音识别、Gemini语音识别 或 阿里Qwen3-ASR。 - 这些在线大模型在断句、上下文理解和抗干扰能力上通常远优于本地模型,能有效解决漏识别问题。
注意:使用这些在线渠道需要:
- 在
菜单 -> 语音识别设置 中配置对应的 API Key。 - 如果服务在国内受限,需要在主界面的“网络代理”处填写您的代理地址。
作为备选:优化本地渠道的最后尝试
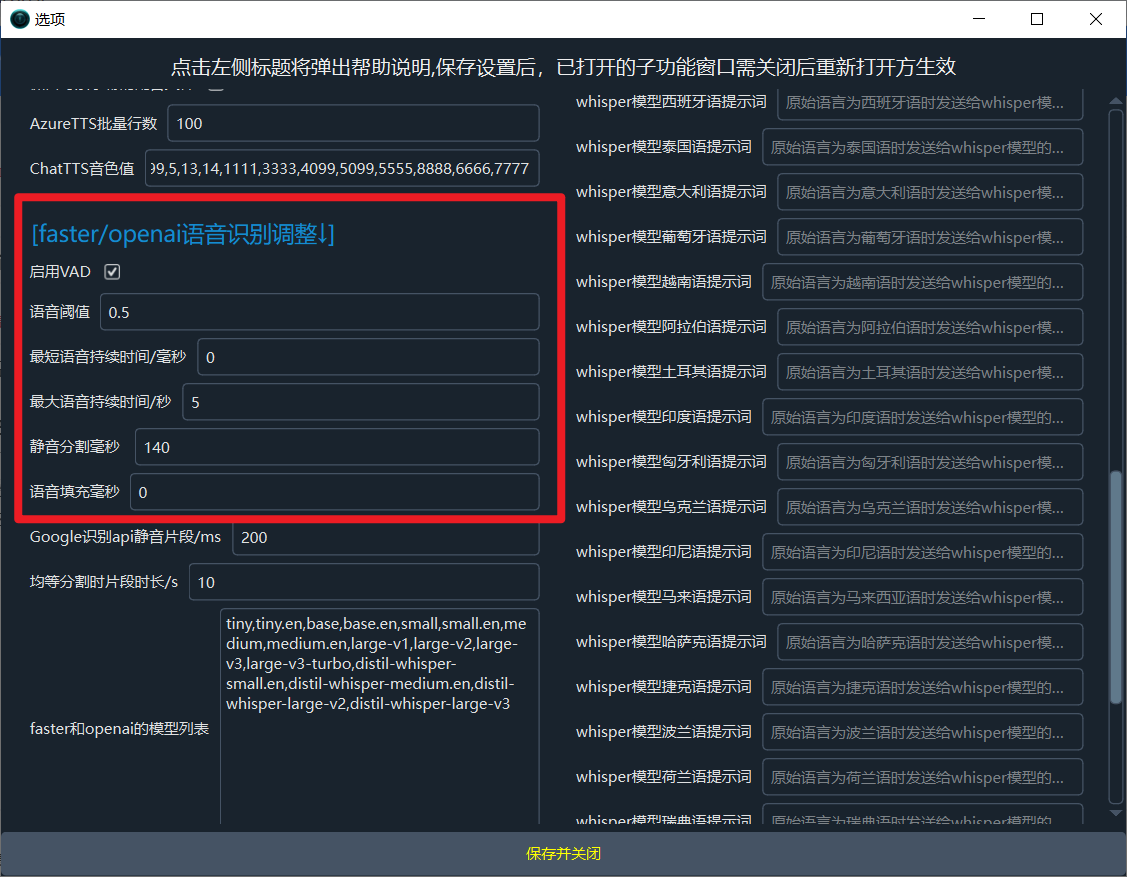
- 在
菜单 -> 工具/选项 -> 高级选项 -> faster/openai语音识别调整 中,尝试将 语音阈值 设置为一个更低的值(如 0.1 或 0.2),并取消勾选“启用VAD”。这会让模型对声音更敏感,但可能会引入更多噪音。
鉴于 faster-whisper 在您的使用场景下问题持续存在,转向效果更可靠的在线AI识别渠道是最高效的解决路径。