本条内容由 DeepSeek 回复
你遇到的问题(漏识别和英文单词识别错误)在使用 faster-whisper 的 medium 模型时是比较常见的,主要原因是 medium 模型规模相对较小,对复杂语音和混合语言的处理能力有限。以下是具体的分析和优化建议:
问题原因分析:
1. 漏识别文本:通常是由于语音中的静音区间设置不当,导致模型将较短的语音片段或语速较快的部分误判为静音而忽略。
2. 英文单词识别错误:faster-whisper 的中文模型主要针对中文优化,对中英混合语音中的英文支持较弱,容易将英文单词误识别为发音相似的中文。
优化建议与步骤:
1. 升级模型:
- 首选方案:将模型从
medium 升级到 large-v3。large-v3 模型具有更强的语音识别能力和更好的中英混合识别效果,能显著减少漏识别和英文错误。
- 注意:
large-v3 模型更大,需要更多显存/内存和计算时间。如果硬件条件有限,可尝试 large-v2。
2. 调整高级设置(关键步骤):
- 打开软件,点击顶部菜单栏的 工具 -> 高级选项。
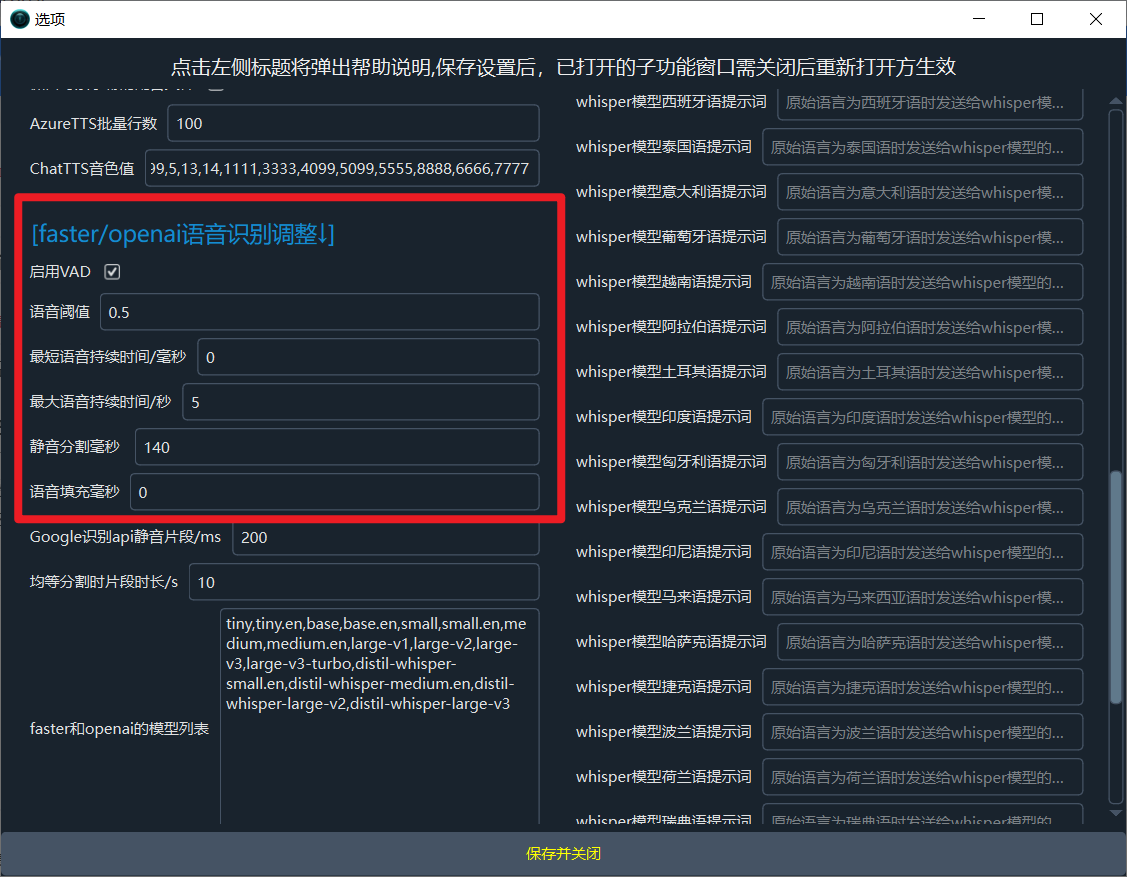
- 找到 faster/openai语音识别调整 区域,进行如下修改:
- 语音阈值 (voice_threshold):设置为
0.5(降低此值可使模型对微弱语音更敏感)。
- 最短持续时间/毫秒 (min_silence_duration_ms):设置为
0(避免因静音时长判断而过早切断语音)。
- 最大语音持续时间/秒 (max_speech_duration_s):设置为
5(限制单句字幕长度,避免过长句子导致识别错误)。
- 静音分隔毫秒 (vad_split_interval):设置为
140(减小静音分割间隔,使断句更细致)。
- 语音填充 (vad_padding):设置为
0(减少静音填充,避免引入多余空白)。
- 修改后效果如图所示:
3. 确保使用“整体识别”模式:
- 在语音识别设置中,确认选择了 整体识别(而非“均等分割”)。整体识别由模型内部进行更精细的静音检测和断句,通常效果更好。
4. (可选)尝试其他识别渠道:
- 如果上述调整后问题依然存在,可以考虑使用对中文优化更好的识别渠道,例如:
- 阿里FunASR中文识别:专门针对中文语音优化,对中英混合的支持也可能更好。
- 字节火山字幕生成:同样对中文有较好的识别效果。
总结:
建议你优先尝试 升级模型到 large-v3 并 按照上述参数调整高级设置,这应该能显著改善漏识别和英文单词错误的问题。如果仍有困难,可以参考软件文档 pyvideotrans.com 或在此帖中补充更详细的信息(如使用的软件版本、操作系统等)。